初识ZooKeeper
概述
ZooKeeper是一个分布式服务框架,用来管理分布式环境中的数据。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
数据模型
Zookeeper会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统
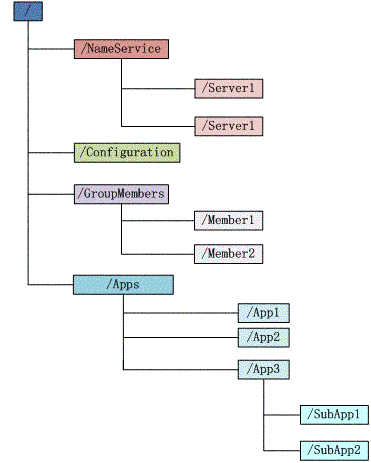
结构特点
- 每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1
- znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
- znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了
- znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
- znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍
ZooKeeper的安装
1. 下载ZooKeeper
从官网下载最新版本
2. 解压
选择一个目录,解压下载的ZooKeeper
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
3. 创建配置文件
解压后文件夹里有一个示例配置文件zoo_sample.cfg,可以直接重命名为zoo.cfg,也可以拷贝一份命名为zoo.cfg
单机模式
# The number of milliseconds of each tick
tickTime=2000
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/path/to/zookeeper/data
# the port at which the clients will connect
clientPort=2181
tickTime: 心跳的时间间隔dataDir: Zookeeper保存数据的目录clientPort: 客户端连接Zookeeper的端口
集群模式
集群模式只需在单机配置的基础上增加下面几个配置项。
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
server.1=192.168.211.1:2888:3888
server.2=192.168.211.2:2888:3888
zookeeper的主节点称为Leader,从节点称为Follower。Leader是根据选举算法由集群节点选举出来的。
initLimit: zookeeper的Leader节点接受Follower节点初始化连接时最长能忍受的心跳时间间隔数(10 2000ms 即20秒)。
syncLimit: Leader与Follower之间发送消息时,请求和应答时间最长不能超过的时间间隔数(5 2000ms 即10秒)。
server.A=B:C:D: A是一个数字,表示这个是第几号服务器;B是服务器的ip地址;C是服务器与集群中的Leader交换信息的端口;D表示选举时使用的端口
除了修改zoo.cfg配置文件,集群模式下还要配置一个文件myid(文件名为myid),这个文件在dataDir目录下,文件内容为A的值。Zookeeper启动时会读取这个文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
4. 启动ZooKeeper服务器
执行如下命令:
$ bin/zkServer.sh start
ZooKeeper的客户端操作
zookeeper目前没有官方的图形界面系统,可使用命令行工具进行操作。客户端命令主要有:create、get、set、ls、stat、rmr
启动客户端
$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0]
列出子项,可以查看根目录下有哪些子项
ls /
创建节点
create /FirstZnode "MyFirstZookeeper-app"
查看节点元数据
get /FirstZnode
修改节点数据
set /FirstZnode "data-update"
查看节点状态
stat /FirstZnode
移除节点
rmr /FirstZnode
[zk: localhost:2181(CONNECTED) 5] ls /
[path, zookeeper]
[zk: localhost:2181(CONNECTED) 6] create /FirstZnode "MyFirstZookeeper-app"
Created /FirstZnode
[zk: localhost:2181(CONNECTED) 7] ls /
[path, zookeeper, FirstZnode]
[zk: localhost:2181(CONNECTED) 8] get /FirstZnode
MyFirstZookeeper-app
cZxid = 0x51
ctime = Mon Jul 16 19:27:27 CST 2018
mZxid = 0x51
mtime = Mon Jul 16 19:27:27 CST 2018
pZxid = 0x51
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 20
numChildren = 0
[zk: localhost:2181(CONNECTED) 9] set /FirstZnode "data-update"
cZxid = 0x51
ctime = Mon Jul 16 19:27:27 CST 2018
mZxid = 0x52
mtime = Mon Jul 16 19:33:09 CST 2018
pZxid = 0x51
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 0
[zk: localhost:2181(CONNECTED) 10] get /FirstZnode
data-update
cZxid = 0x51
ctime = Mon Jul 16 19:27:27 CST 2018
mZxid = 0x52
mtime = Mon Jul 16 19:33:09 CST 2018
pZxid = 0x51
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 0
ZooKeeper的代码示例
// 创建一个与服务器的连接
ZooKeeper zk = new ZooKeeper("localhost:" + CLIENT_PORT,
ClientBase.CONNECTION_TIMEOUT, new Watcher() {
// 监控所有被触发的事件
public void process(WatchedEvent event) {
System.out.println("已经触发了" + event.getType() + "事件!");
}
});
// 创建一个目录节点
zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
// 创建一个子目录节点
zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath",false,null)));
// 取出子目录节点列表
System.out.println(zk.getChildren("/testRootPath",true));
// 修改子目录节点数据
zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1);
System.out.println("目录节点状态:["+zk.exists("/testRootPath",true)+"]");
// 创建另外一个子目录节点
zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo",true,null)));
// 删除子目录节点
zk.delete("/testRootPath/testChildPathTwo",-1);
zk.delete("/testRootPath/testChildPathOne",-1);
// 删除父目录节点
zk.delete("/testRootPath",-1);
// 关闭连接
zk.close();
好处
- 简单的分布式协调过程
- 同步 - 服务器进程之间的相互排斥和协作。此过程有助于Apache HBase进行配置管理
- 有序的消息
- 序列化 — 根据特定规则对数据进行编码。确保应用程序运行一致
- 可靠性
- 原子性 - 数据转移完全成功或完全失败,但没有事务是部分的
用途
- 命名服务 - 按名称标识集群中的节点。它类似于DNS,但仅对于节点
- 配置管理 - 加入节点的最近的和最新的系统配置信息
- 集群管理 - 实时地在集群和节点状态中加入/离开节点
- 选举算法 - 选举一个节点作为协调目的的leader
- 锁定和同步服务 - 在修改数据的同时锁定数据
- 高度可靠的数据注册表 - 即使在一个或几个节点关闭时也可以获得数据